Sub-microsecond xgboost inference
Experiments in cache locality, data structures, cpu isolation, etc
I stumbled this and was amazed that sub-microsecond inference was possible.
And of course, I wanted to see if I could beat it.
Disclaimer: code has been generated by Claude Code. The writing here is entirely my own.
Results
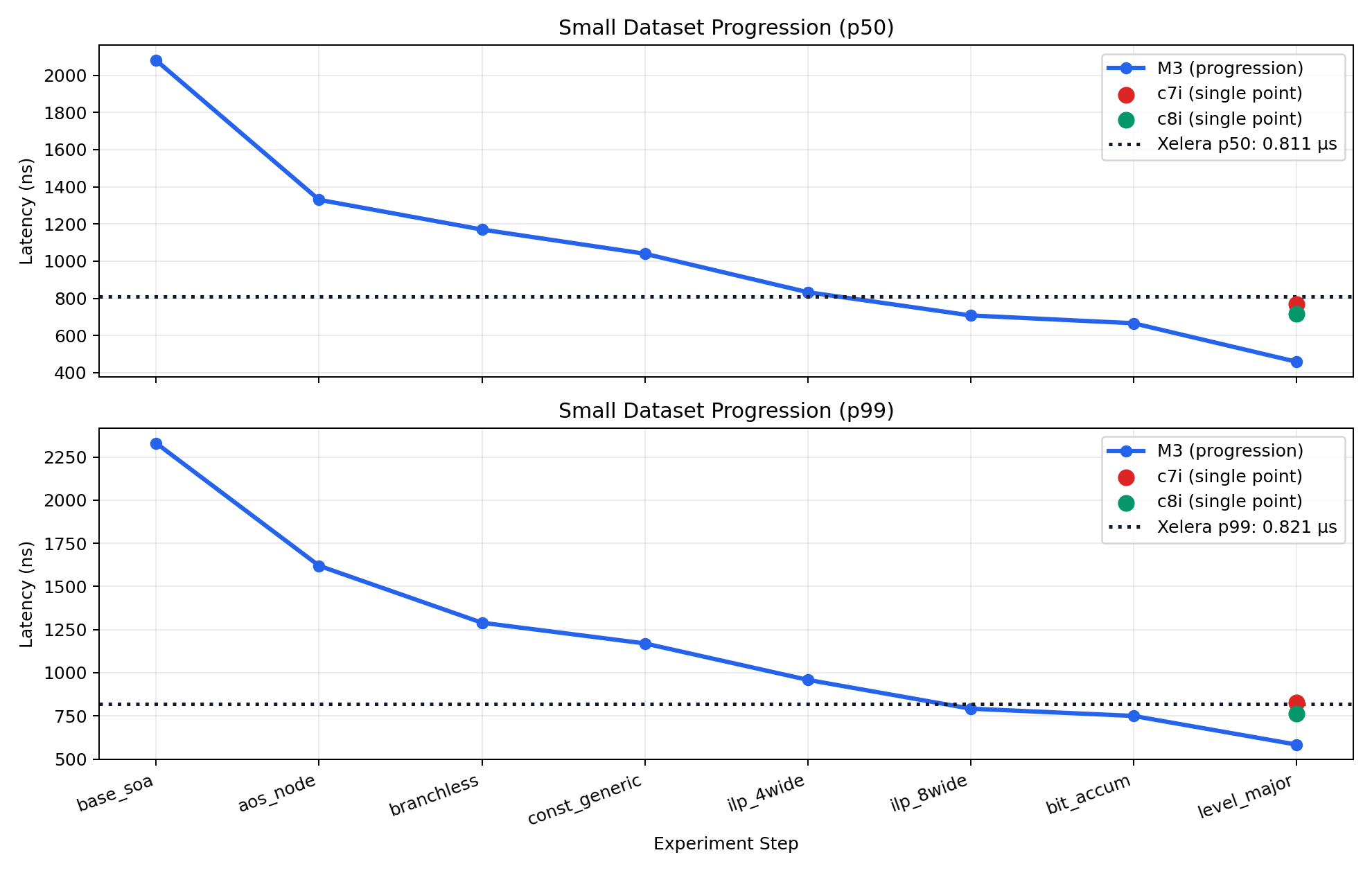
A lot of fun! I was able to get
- 7.8% faster p50
- 2.8% faster p99
- p99 of 798ns
A few caveats. This was not an apples to apples comparison
- different cpus
- different test data
- different models
Refresher
During training, you are picking some subset of features and using them to build a decision tree.
You then repeat this multiple times, yielding multiple trees.
At inference time, you are running through each tree and doing a weighted sum of the resultant leaf value, weighted by the learning rate with some initial prediction added to this value.
Putting some numbers to it, for our small dataset we used 64 features and 200 trees, with a depth of 5. The depth is referring to the distance from the root node to the deepest leaf node.
Decision trees look something like this. You have a serieis of conditionals, with other nodes off of them.
income <= 52k
├─ yes → credit_score <= 680
│ ├─ yes → age <= 30
│ │ ├─ yes → Leaf: -0.20
│ │ └─ no → Leaf: +0.35
│ └─ no → dependents > 2
│ ├─ yes → Leaf: -0.50
│ └─ no → Leaf: +0.10
└─ no → debt_ratio <= 0.45
├─ yes → open_accounts <= 3
│ ├─ yes → Leaf: +0.25
│ └─ no → Leaf: 0.00
└─ no → utilization <= 0.35
├─ yes → Leaf: +0.60
└─ no → Leaf: -0.15 income <= 46k
├─ yes → age <= 28
│ ├─ yes → credit_score <= 690
│ │ ├─ yes → Leaf: -0.80
│ │ └─ no → Leaf: -0.35
│ └─ no → dependents <= 1
│ ├─ yes → Leaf: +0.12
│ └─ no → Leaf: -0.20
└─ no → age <= 55
├─ yes → credit_score <= 700
│ ├─ yes → Leaf: +0.28
│ └─ no → Leaf: -0.60
└─ no → age <= 45
├─ yes → Leaf: +0.18
└─ no → Leaf: 0.00So if we have some input training data
{
"income": 50000,
"credit_score": 700,
"age": 34,
"dependents": 2,
"debt_ratio": 0.40,
"open_accounts": 4,
"utilization": 0.22
}We’d walk through each tree to get its leaf node
- Tree 1 → +0.10
- income <= 52000 → yes
- credit_score <= 680 → no
- dependents > 2 → no (2 > 2 is false)
- Leaf: +0.10
- Tree 2 → +0.28
- income <= 46000 → no
- age <= 55 → yes
- credit_score <= 700 → yes (700 <= 700)
- Leaf: +0.28And finally aggregate those.
Given
initial prediction = 0;
learning rate = 0.1;
raw score = initial prediction + learning rate * sum(tree leaf values)
raw score = 0 + 0.1 * (0.10 + 0.28)
raw score = 0.038Naive Pseudocode
func tree1(input) {
if (input.income <= 52000) {
if (input.credit_score <= 680) {
if (input.age <= 30) {
return -0.20
} else {
return +0.35
}
} else {
if (input.dependents > 2) {
return -0.50
} else {
return +0.10
}
}
} else {
if (input.debt_ratio <= 0.45) {
if (input.open_accounts <= 3) {
return +0.25
} else {
return 0.00
}
} else {
if (input.utilization <= 0.35) {
return +0.60
} else {
return -0.15
}
}
}
}
// similar for tree2
func rawScore(input, trees, initial_prediction, training_rate) {
let sum = 0;
for tree in trees {
sum += tree(input)
}
return initial_prediction + training_rate * sum
}Very simple.
A few performance things we can see that stick out:
-
First thing we can see is that we could calculate each tree concurrently. That is, there is no path dependency on the tree calculations. Calculating the ith tree does not depend on any of the previous tree calcations.
-
If we assume that the naive code implementation has a textbook 101 level tree implementation, with a pointer to a node, then we’ll have a lot of pointer chasing.
-
The other thing that sticks out is the number of if statements. Each one of these is a good chance for a branch mispredict, which will hurt overall latency and really impact p99 values.
On my M3 max, something like that benchmarks at
- min 1.42 µs
- p50 1.50 µs
- p99 1.62 µs
- max 43.46 µs
Reasonably fast for a first pass, but not sub microsecond. And with a pretty gnarly max time.
Flattening
The pointer chasing and cache thrashing felt like low hanging fruit.
Sticking everything in a few arrays should help to drive down latency.
Using level major grouping and clever indexing, we can still walk the trees.
index = tree_number * (1 << level) + positionThen we can take out the branch misprediction by massaging the go left / right calculation.
Instead of
let next_path = if (feature_value > threshold) {
old_path * 2 + 1
} else {
old_path * 2
};We can get that branchless by casting the bool
let next_path = (old_path << 1) | ((feature_value > threshold) as usize)Unrolling
Now that we’ve make cache coherency better and reduced branch mispredictions, we can work on unrolling the loop and leveraging instruction level parallelism, helping to hide memory latency.
So instaed of something like
for tree in trees {
sum += get_leaf(tree);
}We run something like
let base = i * 8;
unsafe {
let mut p0 = 0usize;
let mut p1 = 0usize;
// - snip
let mut p7 = 0usize;
for level in 0..D {
let lvl = level as usize;
let nodes_at_level = 1usize << lvl;
let thresholds = self.level_thresholds.get_unchecked(lvl);
let feat_indices = self.level_features.get_unchecked(lvl);
let off0 = base * nodes_at_level + p0;
let off1 = (base + 1) * nodes_at_level + p1;
let off2 = (base + 2) * nodes_at_level + p2;
// - snip
let off7 = (base + 7) * nodes_at_level + p7;
let f0 = *features.get_unchecked(*feat_indices.get_unchecked(off0) as usize);
let f1 = *features.get_unchecked(*feat_indices.get_unchecked(off1) as usize);
// - snip
let f7 = *features.get_unchecked(*feat_indices.get_unchecked(off7) as usize);
let t0 = *thresholds.get_unchecked(off0);
let t1 = *thresholds.get_unchecked(off1);
// - snip
let t7 = *thresholds.get_unchecked(off7);
p0 = (p0 << 1) | usize::from(f0 > t0);
p1 = (p1 << 1) | usize::from(f1 > t1);
p2 = (p2 << 1) | usize::from(f2 > t2);
// - snip
p7 = (p7 << 1) | usize::from(f7 > t7);
}
let leaf_count = 1usize << D;
let leaves = &self.leaf_values;
sum += leaves.get_unchecked(base * leaf_count + p0)
+ leaves.get_unchecked((base + 1) * leaf_count + p1)
+ leaves.get_unchecked((base + 2) * leaf_count + p2)
+ leaves.get_unchecked((base + 3) * leaf_count + p3)
+ leaves.get_unchecked((base + 4) * leaf_count + p4)
+ leaves.get_unchecked((base + 5) * leaf_count + p5)
+ leaves.get_unchecked((base + 6) * leaf_count + p6)
+ leaves.get_unchecked((base + 7) * leaf_count + p7);
}We can further remove some loop overhead by having the depth of the trees be a generic const.
CPU pinning & isolation
This is my first time playing with this and it was guided heavily by Claude.
Spinning up a c8i server to get something with the latest gen Intel cpu that I can tweak, the following was set:
- taskset -c 2 -> pin the process to CPU 2, so it doesn’t get moved to a different core
- chrt -f 99 -> give the process high priority
- isolcpus=2 -> tells the scheduler to avoid placing regular tasks on our pinned core
- nohz-full=N -> stops the ticks on this CPU? Don’t understand this enough to comment, but seems to be inline with offloading housekeeping
- rcu-nocbs=N -> Offloading hosekeeping
- disabled the hyperthread sibling (core 98 in this case) -> Intel hyperthreads share a physical core. We don’t want housekeeping on the sibling thread to be using the physical core at all
- moved interrupt requests off the pinned core
- disabled CPU idle sleep states (C-states)
-
fixed frequency (presumably this is a power efficiency setting?)
sudo cpupower frequency-set -u 3.9GHz -d 3.9GHz
Running these on a dedicated bare metal AWS instanced results in some dramatically better p99 and max values, with respsect to the p50 values. Especially when compared to my macbook running a zillion other programs.
Learnings
This was a lot of fun. I’m still wrestling with how LLMs have disrupted a lot of the puzzle solving joy I used to get from programming, but this was a fun side quest to see if I could still scratch that itch in some way.
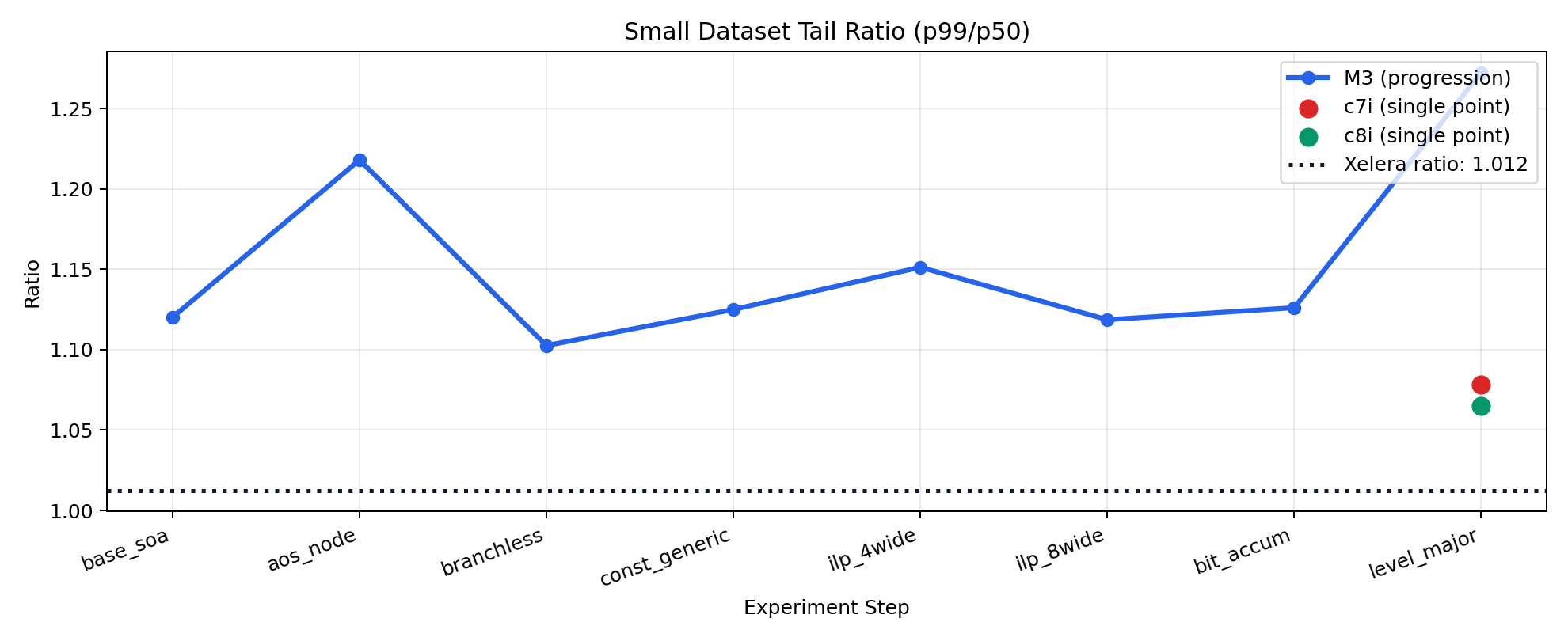
I should have recorded more depth in the the p99 readings. A p99.9 and p99.99 would likely have really shown how the CPU isolation impacted things.
The m3 is fast! I’d imagine SOC redudces memory latency quite a bit, which likely resulted in the smaller latencies we were seeing. The inability to pin a cpu lead to some very high max values though!
A non-AWS instance where we could turn off SMI would have helped to mitigate some of the larger max latencies we were seeing.
I wonder if that also would have let us close the gap between our p99/p50 ratio and Xelera’s. They had a very tight (10 nanos!) difference between the two.